Right: “Informal Definition of Differential Privacy,” courtesy of the National Institute of Standards and Technology
October is Cybersecurity Awareness Month. This article is one of a cybersecurity-focused series.
Last year during the peak of the COVID-19 pandemic in the US, testing and contact tracing failed to quell the spread. Many circumstances — including a decades-old underfunding of state health departments, and slow workforce build – have contributed to this outcome.
However, according to Department of Computer and Information Science Professor Andreas Haeberlen, one of the main reasons contact tracing wasn’t relatively more successful is simple: people don’t’ feel comfortable sharing their information.
“It’s really scary to think of people knowing all the things that you type in your phone,” said Haeberlen. “Like what you’ve had for breakfast, or your medical information, or where you’ve been all day or who you’ve met. All of that data is super super sensitive.”
Haeberlen, whose research centers distributed systems, networking, security, and privacy, believes that differential privacy could be the solution.
“Differential privacy is a way to purpose private information so that you can really guarantee that somebody can’t later learn something sensitive from this information,” said Haeberlen. “[It] has a very solid mathematical foundation.”
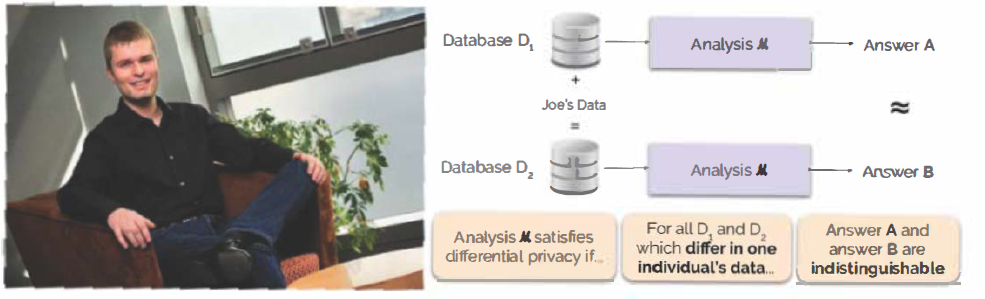
The National Institute of Science and Technology defines differential privacy in terms of mathematical qualification. “It is not a specific process, but a property that a process can have,” said NIST on their website. “For example, it is possible to prove that a specific algorithm ‘satisfies’ differential privacy.”
And so we might assert that, if an analysis of a database without Joe Citizen’s individual data and an analysis of a database with Joe Citizen’s individual data yield indistinguishable results, then differential privacy is satisfied. “This implies that whoever sees the output won’t be able to tell whether or not Joe’s data was used, or what Joe’s data contained,” said NIST on their site.
Haeberlen insists that, with widespread application of differential privacy, user trust is not only no longer a barrier, but that it is not necessarily required. Surrendering our sensitive information to large corporations such as Apple would no longer require a leap of faith.
Building the tools
A popular industry standard of cybersecurity involves adding imprecision into results to purposefully skew them, and thus protect individual user data. Challenges to this application, according to Haeberlen, include the ongoing debate among experts about whether it satisfies differential privacy specifications, and its lack of scalability.
“Fuzzi: A Three-Level Logic for Differential Privacy,” a paper by Haeberlen and fellow researchers Edo Roth, Hengchu Zhang, Benjamin C. Pierce and Aaron Roth, is one of many of Haeberlen’s oeuvre that focuses on developing tools that can do the work for us. The paper presents a prototype called Fuzzi, whose top level of operational logic “is a novel sensitivity logic adapted from the linear-logic-inspired type system of Fuzz, a differentially private functional language,” according to the abstract.
Essentially, a researcher would input data into the tool, define what that data means, and specify what data output they’re searching for. The tool would be able to state if that output satisfies differential privacy specifications, and, if not, what amount of imprecision would need to be added in order to meet specifications.
“The way that we did that was by baking differential privacy into a programming language,” said Haeberlen. “As a practitioner you don’t have to understand what differential privacy is, you also don’t have to be able to prove it.”
In the world of science, imprecision usually means error and gross miscalculation. However, in the more specific realm of differential privacy, imprecision equals security.
“Imprecision is good because it causes the adversary to make mistakes,” said Haeberlen. In this case, the “adversary” is any person or system trying to gain access to sensitive information.
All tools developed by Haeberlen and his team have been made available under open-source license, and companies such as Uber and Facebook are currently releasing data sets using differential privacy.
Visit Professor Andreas Haeberlen’s page to learn more about his current projects and recent publications.